 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
美东时间周二,Meta宣布推出迄今为止最强大的开源模型——Llama 3.1 405B,同时发布了全新升级的Llama 3.1 70B和8B模型。

该公司表示,这是对 4 月份发布的Llama 3的基础上进行了重大更新,Llama 3.1主要用于驱动聊天机器人,可以进行八种语言的对话,编写更高质量的计算机代码,并可以解决更复杂的数学问题。
开源首次击败当今最强闭源模型
4月公开的两个Llama 3小参数模型8B和70B表现不俗,此次的更新令开发者们对最大参数版本的强悍性能充满期待。
Llama 3.1系列,包括405B、8B和70B三个版本,其中405B版本以其4050亿个参数的规模成为全球最大的开源AI模型。
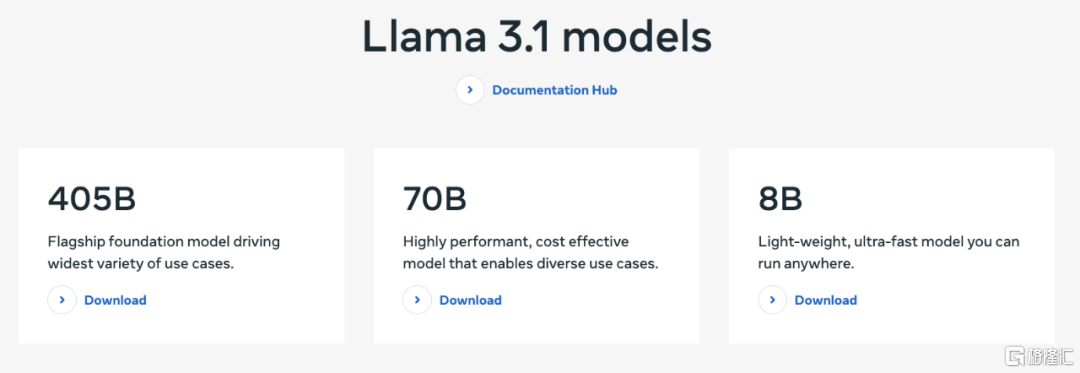
这一发布在AI领域引起了巨大轰动,标志着开源AI模型在性能上首次与闭源模型如OpenAI的GPT-4o和Anthropic的Claude 3.5 Sonnet相媲美,甚至在某些方面取得了领先。
首先,模型支持多语言对话和代码生成,能够处理复杂的数学问题,并具有改进的推理能力。例如,它可以在八种语言(英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语)中进行高质量的对话,编写更高质量的计算机代码,并解决更复杂的数学问题。
此外,Llama 3.1还具有生成式AI功能,能够通过文本提示生成图像,并允许用户上传面部图像以在不同场景中生成描绘。
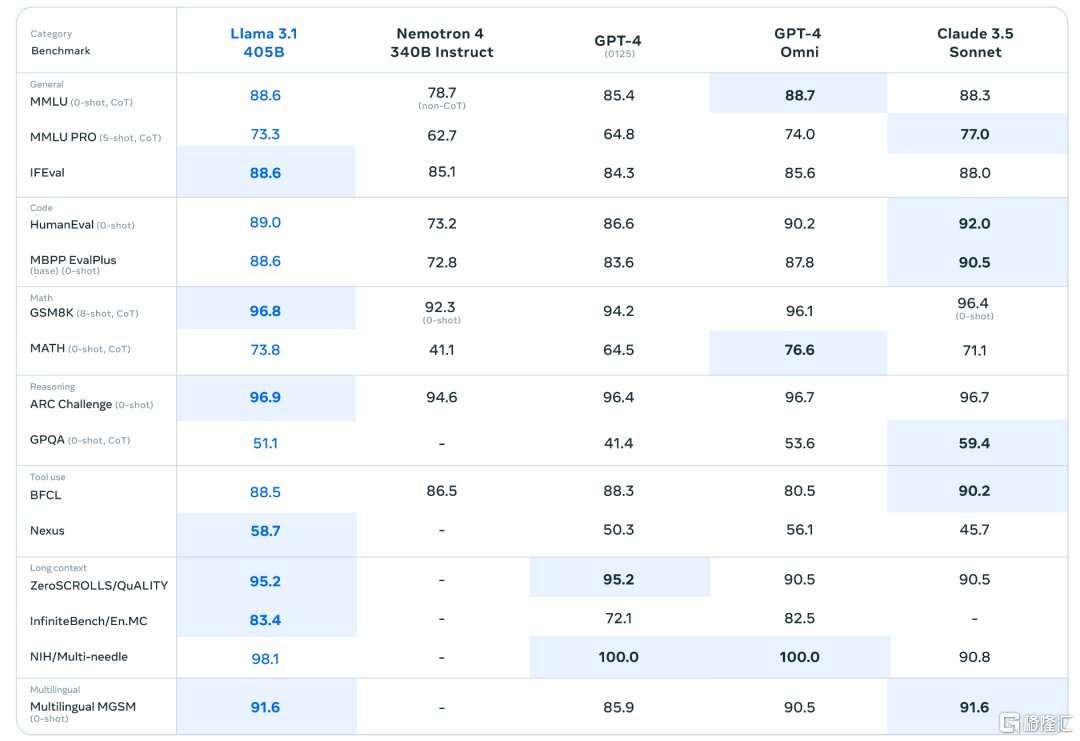
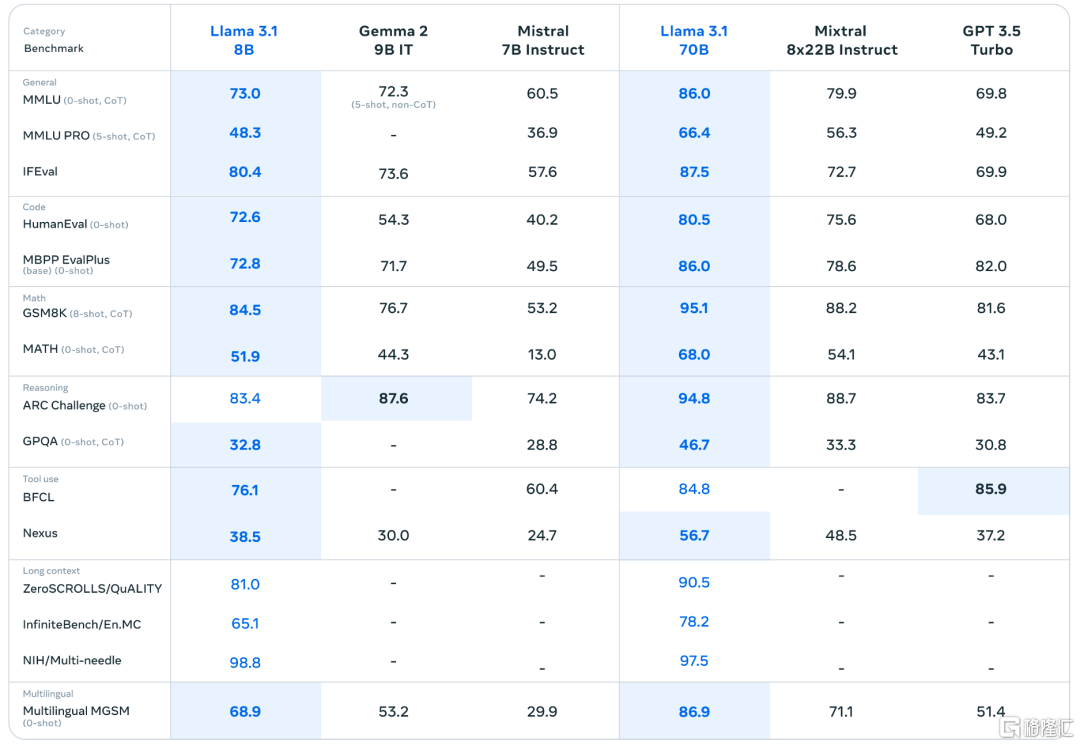
在性能上,Llama 3.1 405B在150多个基准测试集中的表现卓越,与当前最先进的闭源模型相比具有竞争力。它在数学、工具使用、多语言翻译等任务中展现出色,甚至在某些测试中超越了GPT-4o。
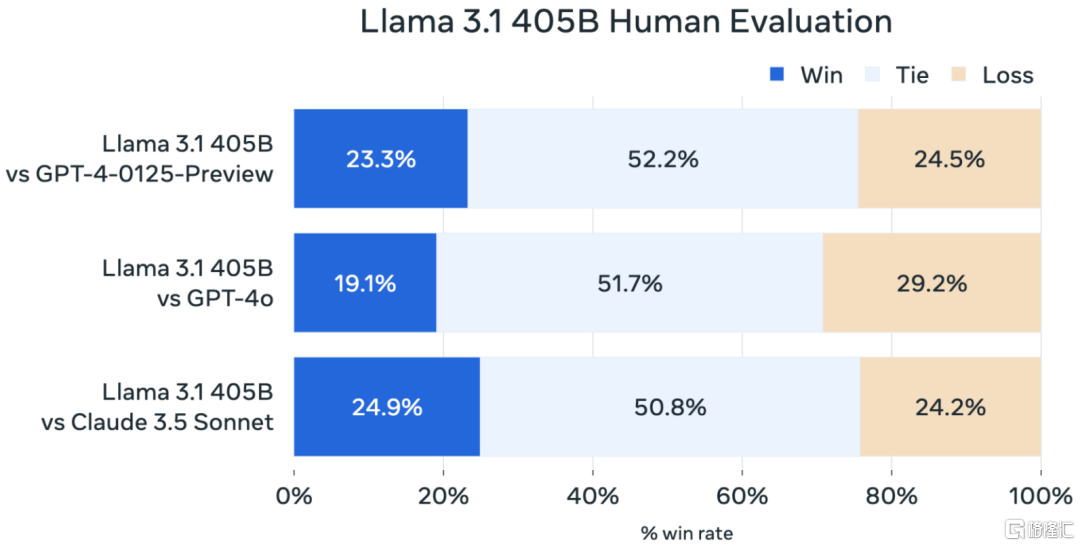
这一成就证明了开源模型在资源投入、研发团队等方面的优势,以及开源社区在推动技术创新方面的潜力。
Meta对Llama 3.1系列模型的训练投入了巨大的计算资源,使用了超过16000个英伟达H100 GPU,并在15万亿个token上进行了训练。这种规模的训练不仅需要强大的硬件支持,还需要优化的训练堆栈和策略。
扎克伯格声称,Meta的Llama 3系列模型需要“数亿美元”的算力来训练,但他预计未来的模型将花费更多。他补充说:
“未来需要数十亿或更多美元的算力。”
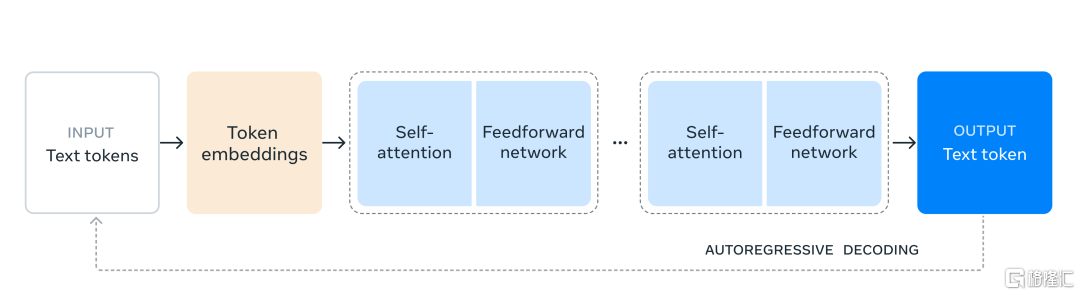
Meta通过迭代的后训练程序、监督微调和直接偏好优化等技术,提高了模型的性能和指令遵循能力。
此外,Llama 3.1系列模型的发布还伴随着一系列生态系统的支持。
Meta与超过25个合作伙伴,包括亚马逊AWS、英伟达、Databricks、Groq、戴尔、微软Azure和谷歌云等,共同推出了相关服务,以支持开发者微调和训练自己的模型。
这些合作伙伴提供的服务包括全套的微调和训练支持、低延迟低成本的推理服务,以及在主要云平台上的模型服务。
Meta还更新了Llama模型的许可证,允许开发者使用Llama 3.1系列模型的输出来开发第三方AI生成模型,进一步推动了开源社区的发展。
同时,Meta也在积极构建Llama生态系统,发布了参考系统和新的安全工具,以鼓励开发者在更多地方使用Llama模型。
重塑AI生态与未来
业内人士认为,Llama 3.1系列模型的发布,不仅是Meta在AI领域的一个重要里程碑,也是全球AI技术发展的一个重要转折点。它证明了开源AI模型在性能、灵活性和创新潜力上的巨大优势,为全球AI研究和应用提供了新的动力和方向。
Meta首席执行官马克·扎克伯格(Mark Zuckerberg)在多个场合强调了开源AI的重要性,此次还亲自写了篇长文《Open Source AI Is the Path Forward》,他认为开源是推动AI技术民主化和普及的关键。

通过开源,更多的开发者和公司能够访问、使用和基于Llama 3.1进行创新,这不仅有助于降低技术的门槛,还能促进全球AI生态系统的多样化发展。
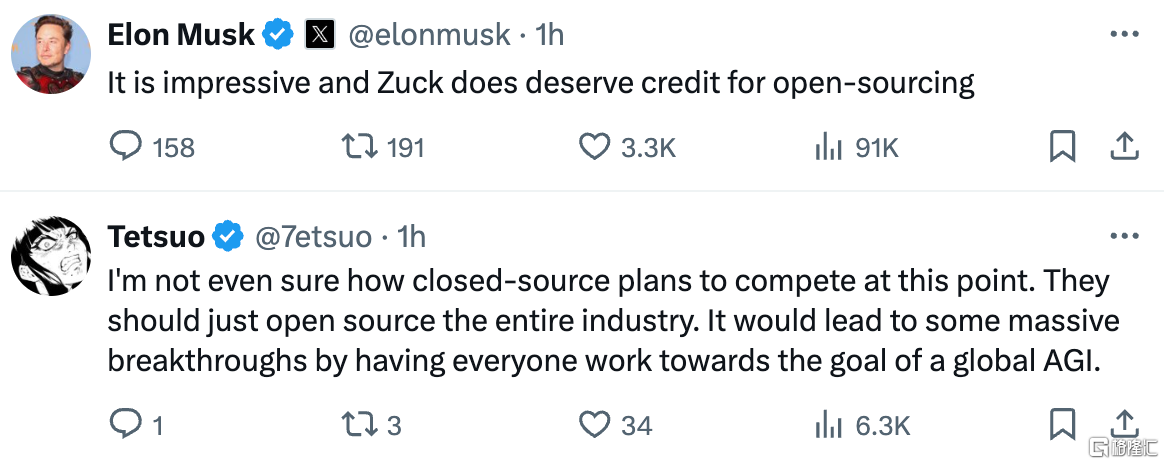
马斯克称赞了扎克伯格为开源社区做出的贡献。用户@7etsuo说,
“我甚至不确定闭源在这一点上打算怎么竞争。他们应该也向整个行业开放。让每个人都致力于AGI目标,从而带来一些重大突破。”
随着Llama 3.1的发布,业内人士称,可以预见,未来AI技术将更加普及,创新将更加多元,而开源社区将成为推动这一进程的重要力量。
正如扎克伯格在其长文末尾所描述的愿景那样:
我相信 Llama 3.1 版本将成为行业的一个转折点,大多数开发人员将开始转向主要使用开源技术,我期待这一趋势从现在开始持续发展……共同致力于将 AI 的福祉带给全球的每一个人。
附上模型下载地址:
https://huggingface.co/meta-llama
https://llama.meta.com/



