 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
近期UI交互等多模态大模型持续迭代,有望加速AI Agent落地节奏。在本篇报告中,中金研究从能力升级和场景创新两个维度探索AI Agent落地方式和形态,中金研究认为AI Agent是连接大模型和现实世界的“最后一公里”。
摘要
能力升级:UI识别和操作模型推动垂直场景生产力提效。Ferret-UI:苹果首个手机端UI多模态大模型,得益于使用了大量UI数据集训练和引入了“任意分辨率”技术,擅长理解屏幕微小元素,在大多数移动端基础UI任务中超越GPT-4V。Adept:推出Fuyu系列多模态模型,Fuyu-8B架构简洁,低延时、灵活性高,Fuyu-Heavy具备出色的UI理解和数学推理能力,专为Digital Agent设计。OpenAI GPT-4o:原生多模态赋能,多模态交互和情绪理解能力出色,可有效提高人机交互体验。
能力升级的意义:加速AI Agent落地节奏,赋能AI终端推动换机潮。软件维度:UI及其他专有大模型的推出能够增强或补齐AI Agent能力,使得Agent离我们日常工作生活越来越近,ToB和ToC传统软件均有望迎来新一轮的生产力提效;相较于传统软件工具,AI Agent具有更强的适应性,有望将API和软件工具串联起来,成为连接大模型和现实世界的“最后一公里”。终端维度:面向智能交互的多模态大模型是端侧Agent落地的基石,有望赋能AI PC和AI手机等终端,加速端侧设备换新潮。
场景创新:AI Agent有望开拓更丰富落地场景,Automation、IPA、TRPG初露曙光。依托于AI Agent的感知环境、自主决策和行动等功能,兼具工具和情感属性的特点,AI Agent有望开拓出更多更丰富甚至全新的应用场景。Automation(业务流程自动化):Adept Experiment助力企业实现跨平台工作流,降低软件使用门槛。IPA(智能个人助理):Google Astra具有理解、推理和记忆的功能,通过摄像头广泛吸收信息和识别场景;Dola.AI能够便捷高效地帮助用户安排个人日程,产品形态简洁。TRPG(桌上角色扮演游戏):盗梦笔记以AI Agent为主持人,提供更有趣和个性化的玩家游戏体验。
风险
技术发展不及预期;商业化落地进展不及预期;行业竞争加剧。
正文
能力升级:UI识别和操作模型推动垂直场景生产力提效
Ferret-UI:苹果首个手机端UI多模态大模型,擅长理解屏幕微小元素
2024年4月8日,苹果的端侧AI论文提出多模态大语言模型Ferret-UI[1],能够更有效地理解手机屏幕信息并与之进行交互,具备引用(referring)、定位(grounding)和推理功能[2],不仅超越大多数开源UI(User Interface,用户界面)多模态模型,并且在大多数移动端基础UI任务(elementary UI tasks)中超越GPT-4V。中金研究认为,Ferret-UI模型的推出有望为苹果在端侧部署AI建立一定先发优势,同时进一步验证了在特定场景进行针对性优化(例如技术架构、数据集等方面)的垂类模型(例如UI多模态大模型)的能力表现或优于通用大模型。
功能维度:Ferret-UI采用大量UI数据集,更擅长理解细节和微小元素
Ferret-UI基于2023年苹果与哥伦比亚大学研究团队联合发布的多模态大模型Ferret构建,更聚焦移动端用户的交互体验,并根据移动端UI屏幕的特点进行了以下针对性优化:1)引入“任意分辨率”(any resolution,简称anyres)技术,能够识别和处理任意宽高比的屏幕,并识别图标、按钮、文本等小尺寸图像/微小元素;2)在理解屏幕整体功能的基础上,能够基于人机对话自主推断任务并提出相应的可行操作,从而帮助用户完成界面导航等开放式任务,中金研究认为这是AI Agent在手机端感知环境、进行决策并提出建议的初步呈现。
图表1:Ferret-UI能够有效识别图标、按钮等微小元素和理解细节
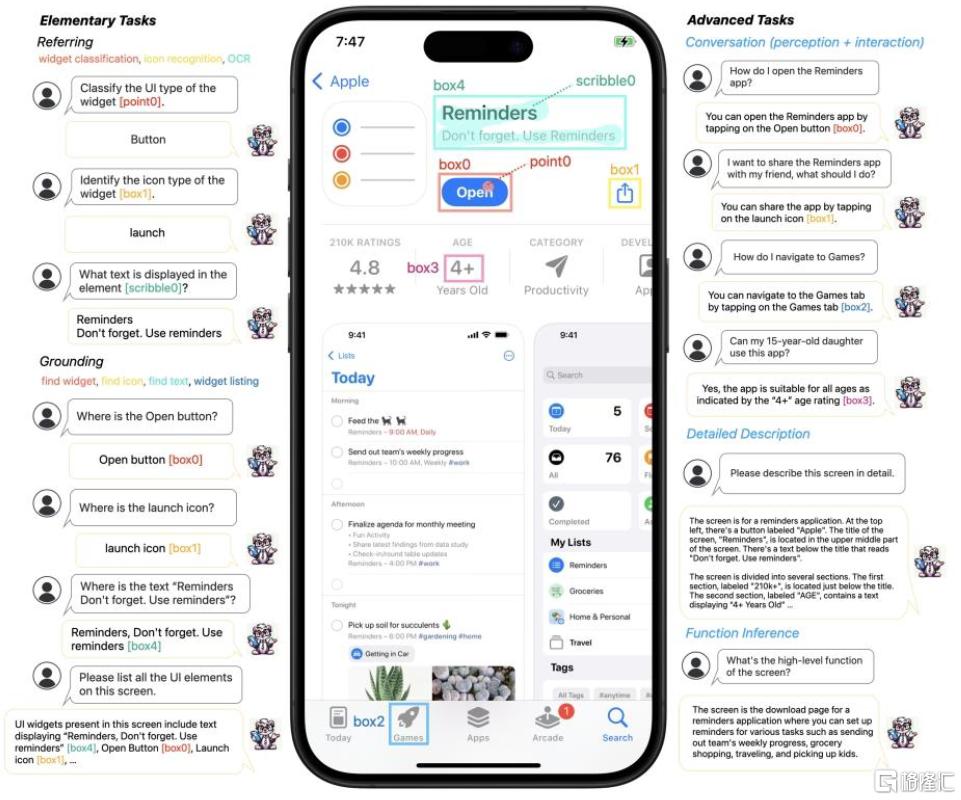
资料来源:You, Keen et al. “Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs.” (2024),中金公司研究部
技术维度:Ferret-UI引入“任意分辨率”技术以适应UI场景任务
Ferret的技术架构包含经预训练的图像编码器、空间感知视觉采样器和纯解码器语言模型三个组成部分:图像编码器用于提取图像嵌入,即将图像转化为模型能够理解的向量空间;空间感知视觉采样器专为实现“混合区域表示”技术而构建,能够处理不同形状之间的稀疏性差异,用于提取区域连续特征;语言模型用于联合图像、文本和区域特征进行信息的汇总分析。其中,“混合区域表示”(Hybrid Region Representation)技术是在LLM范式下提升Ferret模型引用、定位能力以及二者间紧密程度的新式有效手段,其“离散坐标+连续视觉特征”的区域表示方式能够更灵活地将点、框或复杂多边形等不同形状的指定区域转换为适合语言模型处理的格式,从而有效提高模型理解和描述图像元素的准确性。
图表2:Ferret模型的技术架构
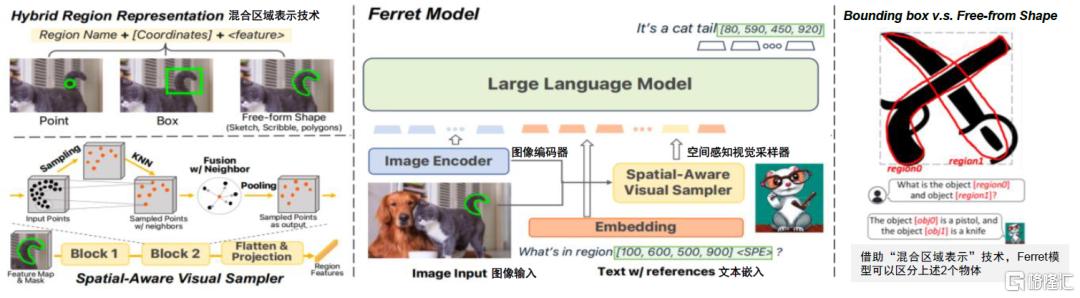
资料来源:You, Haoxuan et al. “Ferret: Refer and Ground Anything Anywhere at Any Granularity.” ArXivabs/2310.07704 (2023): n. pag.,中金公司研究部
Ferret-UI共有base和anyres两个版本,其中,Ferret-UI-base直接沿袭Ferret的架构,Ferret-UI-anyres则进一步融入细粒度图像功能,实现“任意分辨率”技术以处理不同宽高比的屏幕。细粒度图像功能通过放大细节来解决UI屏幕中识别较小对象的问题,从而提升模型对UI元素的理解精度。Ferret-UI-anyres工作流程主要包含以下步骤:1)获取屏幕图片,分别将其转换为低分辨率完整图像和分割成Sub0、Sub1两个子图,从而更好地捕捉UI细节;2)将上述三张图输入图像编码器中获得三个单独的特征编码,并利用映射层对其执行特征变换;3)将文本信息输入文本嵌入器和视觉采样器,后者会将含有区域信息的文本生成区域连续特征;4)将图片编码、文本嵌入和区域连续特征全部输入LLM并生成最终结果。
图表3:Ferret-UI-anyres用“放大镜”观察并识别UI界面,类似于自动驾驶的前融合技术
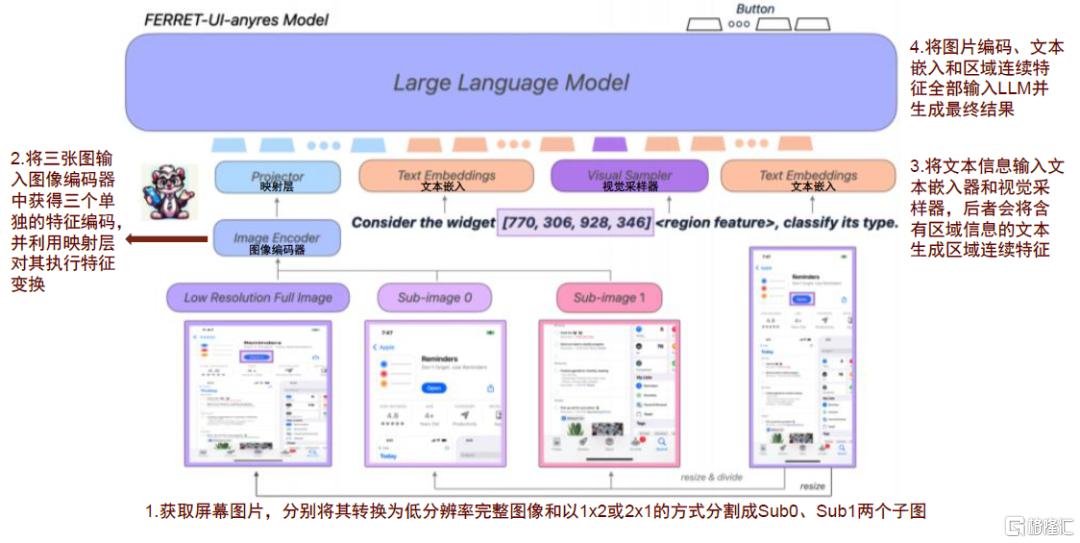
资料来源:You, Keen et al. “Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs.” (2024),中金公司研究部
Adept:推出Fuyu系列多模态模型,加速Digital Agent落地
Adept自创立以来便一直广受大众关注,近期Adept在Fuyu-8B模型的基础上,进一步发布专为Digital Agent设计的多模态模型Fuyu-Heavy。中金研究认为,此番Adept升级其旗下模型的多模态理解和推理能力,或意味着Adept向Agent落地更进一步。
Adept:致力于开发能够实现软件自动化操作的AI Agent
Adept由David Luan联合Ashish Vaswani和Niki Parmar于2022年4月正式创立。联合创始人Ashish Vaswani和Niki Parmar[3]曾就职于谷歌AI研究部,并于2017年合作提出Transformer架构,是AI大模型时代技术基石的重要奠基人。而David Luan曾先后担任OpenAI工程副总裁和Google Brain主管,并基于Transformer架构构建了GPT-2和GPT-3模型,同样具备深厚的技术背景。
Adept的目标是基于生成式AI建立全新的通用操作工具,使其充当AI Teammate来帮助人类完成工作,实现软件自动化操作。2022年以来,Adept先后发布Action Transformer(ACT-1,2022)、Fuyu-8B(2023)和Fuyu Heavy(2024)大模型,其中ACT-1具备UI图形理解和执行任务的能力,并可连接浏览器执行点击、输入、滚动等具体操作,可视作基础模型(须学会使用各种软件工具、API和网页应用)的雏形,而Fuyu系列大模型专为Digital Agent设计,支持任意图像分辨率、回答图形图表相关问题和对屏幕图像进行细粒度定位。此外,Adept于2023年9月正式发布由ACT-2模型驱动的Adept Experiments[4],其上线的首个实验可以支持企业用户创建用于Web的小型工作流构建器,从而帮助用户简化任务流程、提高工作效率,中金研究将在后文对其做更深入的探讨。
截至目前,Adept共获得两笔投资,总融资金额达4.15亿美元[5]。2022年成立之初,Adept即得到包括LinkedIn创始人Reid Hoffman、特斯拉前AI总监Andrej Karpathy在内的多名业界名人6500万美元的注资。2023年3月,Adept再获来自由顶级风投机构General Catalyst和Spark Capital领投[6],微软、英伟达等业界大厂跟投的总计3.5亿美元融资,公司估值突破10亿美元[7]。
图表4:Adept产品和融资发展历程

资料来源:Adept官网,中金公司研究部
Fuyu-8B:简洁而强大的多模态开源模型,具备多种图文任务处理能力
Fuyu-8B具备强大的复杂图像理解能力和高可拓展性。2023年10月,Adept正式发布并开源了80亿参数多模态大模型Fuyu-8B[8]。Fuyu-8B不仅具备图表、图形和文本理解能力,还能够厘清复杂图像中元素的相互关系,并可根据用户指令正确归纳所需的图表信息。此外,Adept在Fuyu模型基础上进一步开发了具备OCR、UI元素细粒度识别与问答等功能的内部模型,展现出Fuyu系列模型强大的可拓展性,为未来Adept在UI识别和操作领域发展奠定基础。
Fuyu-8B架构简洁,具备低延时和高灵活性的特点。Fuyu-8B采用decoder-only架构,无图像编码器,并支持处理任意分辨率的图像。工作流程上,Fuyu-8B首先将输入图像分割成若干补丁(patches),然后将其直接线性投影到Transformer第一层,省略了嵌入查找(Embedding Lookup)步骤,同时利用图像转换行符号告知模型何时断行,最后由Transformer解码器输出最终结果(或类似于ViT架构)。这一工作流程简化了Fuyu-8B的训练和推理过程,大幅提高了模型的运行速度,使其能够在100毫秒内即可反馈大尺寸图像的处理结果。
图表5:Fuyu-8B采用decoder-only架构,可支持处理任意分辨率的图像
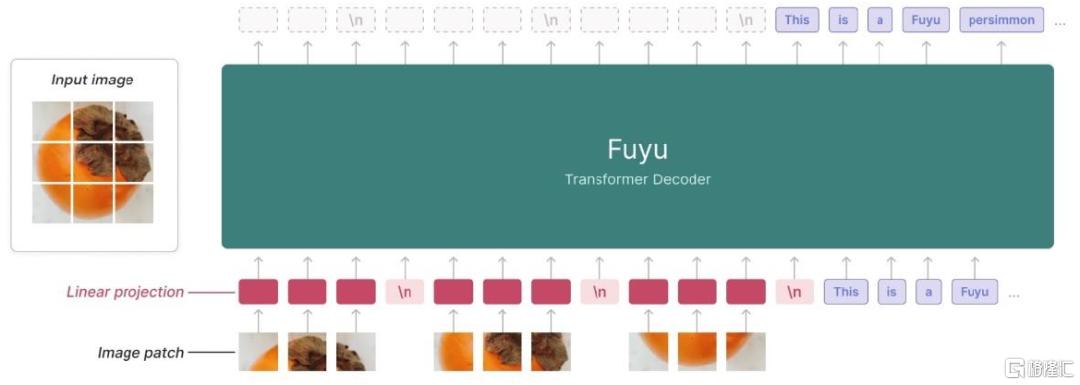
资料来源:Adept官网,中金公司研究部
Fuyu-Heavy:专为数字Agent设计,UI理解能力出众
Fuyu-Heavy基于Fuyu-8B打造,是未来Agent产品的基础模型。2024年1月,Adept正式发布Fuyu-Heavy多模态模型[9],其研究团队花费4个月时间在Fuyu-8B的基础上着力解决多模态模型在文本和图像数据方面的诸多问题:1)大规模图像数据输入造成的内存使用量激增和云存储输入输出限制;2)图像模型的不稳定性;3)高质量图像数据的稀缺性;4)图像文本任务比例的平衡性。中金研究认为,一方面,Fuyu-Heavy验证了Fuyu系列模型的可拓展性,未来可以scale up;另一方面,Fuyu-Heavy作为“小而精”[10]垂类模型能够适配更多平台,有望为Adept发布Agent产品奠定模型基础。
Fuyu-Heavy具备出众的UI界面理解和数学推理能力。根据公司官网,截至2024年1月,Adept宣称Fuyu-Heavy为全球仅次于GPT-4V和Gemini Ultra的第三强多模态模型,而Fuyu-Heavy的规模仅为后者的5%-10%[11]。模型能力方面,Fuyu-Heavy不仅具备强大的多模态推理能力,尤其是UI界面的理解能力,还能够求解较为复杂的数学问题,表现出较强的数学推理能力。此外,在传统多模态基准测试和标准文本基准测试中,Fuyu-Heavy与Gemini Pro、Inflection-2表现相当。
图表6:Fuyu-Heavy具备出众的UI理解能力和数学推理能力
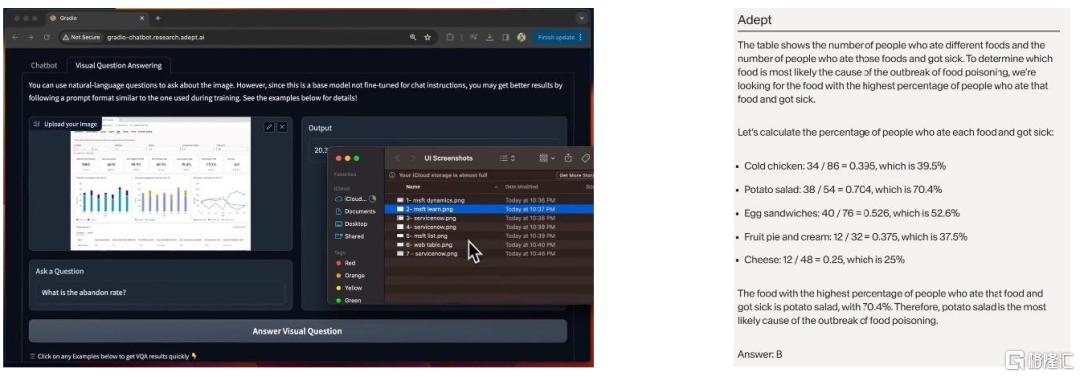
资料来源:Adept官网,中金公司研究部
场景创新:AI Agent有望开拓更丰富落地场景,Automation、IPA和TRPG初露曙光
尽管AI技术潜力巨大、AI应用长期有望百花齐放,但海内外普遍认为目前尚未找到能够实现爆发式增长和规模化收入增量的AI场景,AI原生/杀手级应用尚未出现,缺少应用方向或已成为AI板块继续上行的重要担忧。目前关于AI应用落地相对较快的方向的市场共识是知识库、个人助理、代码编写和情感陪护等,中金研究认为依托AI Agent的环境感知与交互、自主规划和行动等功能,兼具工具和情感属性的特点,AI Agent有望开拓出更丰富甚至全新的应用场景。下文中金研究将以Adept Experiment、Google Astra、Dola.AI和盗梦笔记为例,介绍业务流程自动化(Automation)、智能个人助理(IPA)和桌上角色扮演游戏(TRPG)三大创新场景。
Adept Experiments:Workflows助力企业实现跨平台工作流
Adept Experiment基于ACT-2模型,帮助企业完整执行软件工作流(Workflows),实现软件侧的泛化能力。Workflows由ACT-2(基于Fuyu-Heavy模型微调得到)提供支持,对于UI理解、数据理解和执行指令进行进一步优化,实现端到端的AI agent功能。Workflows依托于软件使用的感知维度,直接通过像素感知屏幕,通过坐标和点击进行软件维度流程操作。其功能主要致力于快速学习流程性或复杂任务,过程中需要前期的详细提示。据Adept官网,与Adept合作的企业客户体验到超95%的可靠性[12]。
Adept Workflows具备跨平台执行工作流的能力,可以快速学习和执行工作流,降低软件使用门槛。Workflows具备跨平台延展性,能够理解屏幕上下文,嫁接不同软件的工作流程,可实现跨软件操作,在文本简洁、HTML难以编程运作的场景也可实现工作流执行。例如,招聘者可以基于Adept定义工作流程,自动对接候选人的邮件申请,一键获取候选人邮件及空闲时间,并转移到面试轮次。
图表7:Adept能够处理重复性工作任务,例如在Excel表格中检查招聘候选人邮箱是否有效
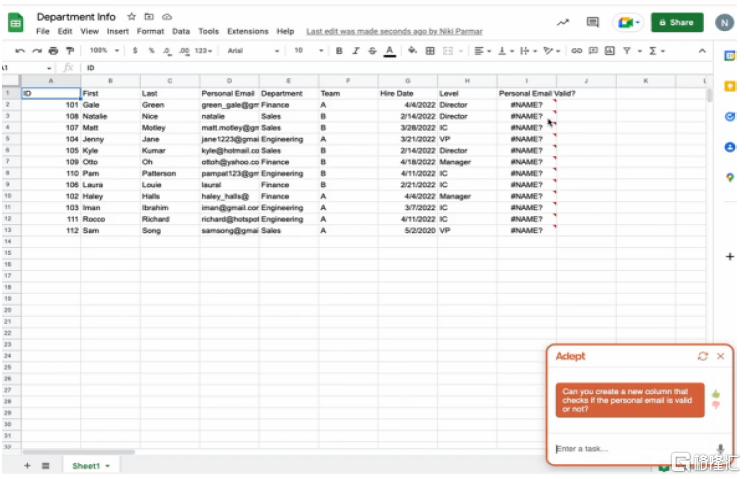
资料来源:Adept官网,中金公司研究部
图表8:Adept能够跨平台执行工作流,例如帮助保险代理人从邮件提取理赔信息,并填入其他软件的表单中
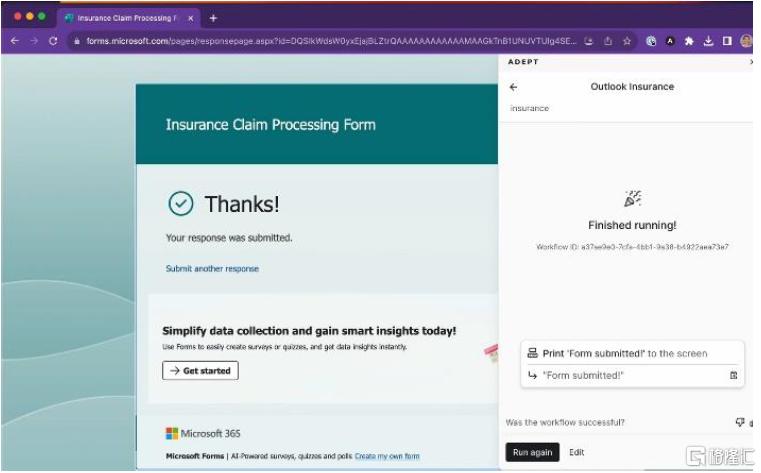
资料来源:Adept官网,中金公司研究部
Google Astra:多模态交互助手,布局端侧模型和终端设备
Project Astra以Gemini模型为基础,能对多模态信息实时推理,感知用户所处环境,是Google探索AI Agent应用的重要里程碑。为了使Astra在日常生活中真正实用,DeepMind采用了视频连续编码、视频和语音嵌入事件时间轴、缓存信息的技术,以突破原有Agent存在的滞后或延迟问题。
Astra具有理解、推理和记忆的功能,通过摄像头广泛吸收信息和识别场景,从而更好满足用户需要。以领先的Gemini模型作为底层支撑,Astra交互更加迅速、拟人化和自然化。例如,工作场景中,举起手机对准代码,Astra可迅速解释代码的构成和功能,提高工作效率;生活场景中,通过建筑物的外观,Astra可定位并介绍所在的地理位置,改善出行体验。Astra视觉识别和记忆性能强大,可高效记忆上下文和空间物体,例如能寻找一晃而过的眼镜位置。中金研究认为,Astra能多场景即刻响应用户需求,有望为Google进一步打造跨软件和系统的AI Agent应用赋能和积累经验。
模型侧,云端模型侧重长文本、端侧模型能够实现离线交互,拓展Agent的端侧生态。Google发布Gemini 1.5 Flash和Pro模型,分别支持100万/200万token长文本,改善记忆问题,此外,即将在API层面更新视频输入拆帧能力、实现并行执行请求和已上传文本缓存功能。Gemini Nano端侧模型则定位手机端小模型,无需联网、在系统层面集成交互性能,即可在电话交互、调用手机应用过程中低延时实现。
图表9:Astra记忆能力突出,例如能迅速报出之前摄像头一晃而过的眼镜位置

资料来源:Google官网,中金公司研究部
图表10:用户可佩戴智能眼镜使用Astra,例如其能识别草图并建议用户添加高速缓冲存储器以提升方案速度
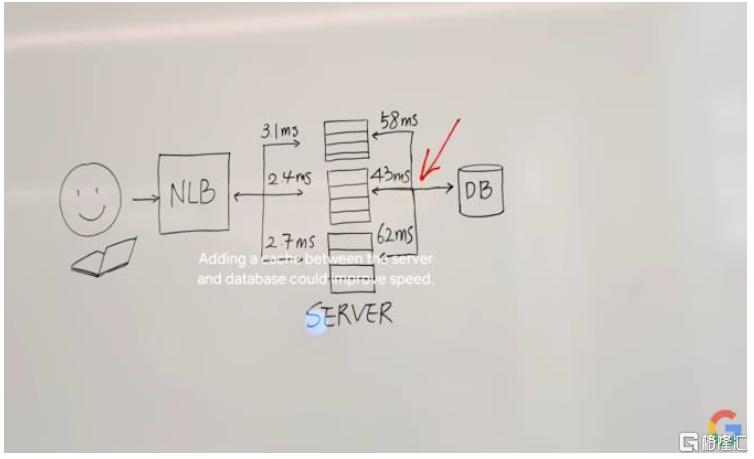
资料来源:Google官网,中金公司研究部
Google完成端侧设备拓展,Google智能眼镜也能对其支持,意味着未来脱离手机和电脑使用AI Agent成为可能。从演示效果看,智能眼镜上使用Astra同样流畅,可提供工作改进方案建议、识别物体、数学问题辅导、与宠物互动,使AI融入了日常生活的方方面面。中金研究认为,眼镜等终端设备推出有望推动AI Agent扩展更多应用场景快速渗透,夯实Google生态。
Dola.AI:个人日程助手,助力释放更多时间价值
Dola.AI是由Orion Arm公司开发的最新个人AI日程助手。Dola.AI的主要功能是以较小的时间成本帮助用户高效地安排各类个人日程,从而为他们释放更多的时间用于工作和生活。Dola.AI的研发团队来自美国麻省理工学院、复旦大学等多所海内外顶尖高校,并在3个月内迭代了百余个版本,目前支持在Apple Messages、WhatsApp、Telegram、Line和微信等多个平台使用,并已在全球范围内积累了超15万用户[13]。中金研究推测,Dola.AI的技术实现路径可能是“多模态模型+工程化”,更多是工程能力上的进一步积累。
与传统日历软件相比,Dola.AI具有以下优势:1)支持用户通过自然语言交互设置日程安排,并可根据用户时间规划偏好自动设置预期用时,极大程度地提升了用户制定、修改和取消日程的便捷程度;2)支持语音、图像、文本等多模态信息的输入,能够将人们从会议纪要、提取图片信息等琐碎任务中解放出来;3)具备上下文记忆和多设备日程同步能力,支持用户随时随地更新日程;4)可无缝集成至现有社交软件,无实体应用或小程序,产品架构简洁,是现有的最小可行产品(Minimum Valuable Product,MVP)。
图表11:Dola.AI能够识别文本、语音、图像等多模态信息并自动导入iPhone日历
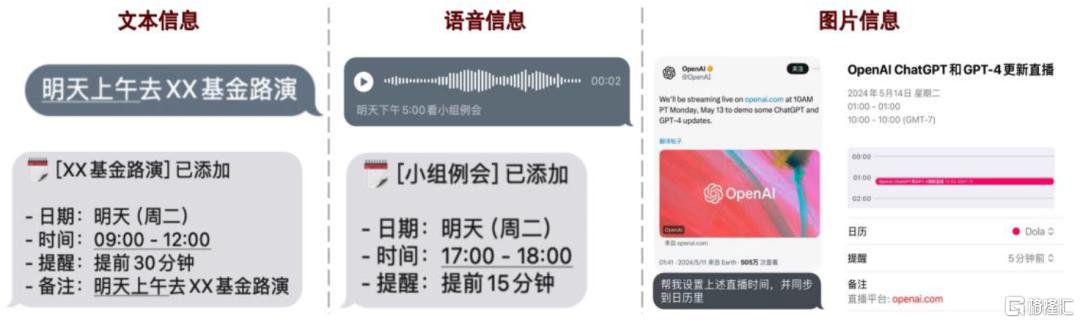
资料来源:Dola.AI,中金公司研究部
图表12:Dola.AI能够与用户通过自然语言交互并设置、修改和删除相应日程
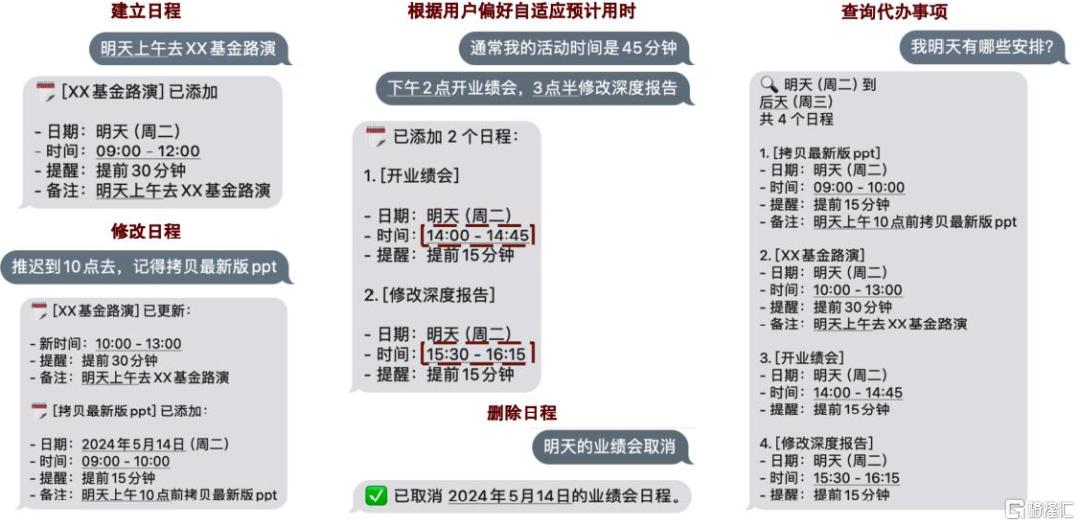
资料来源:Dola.AI,中金公司研究部
盗梦笔记:以AI Agent为主持人,提供更有趣玩家游戏体验
桌上角色扮演游戏(Tabletop Role-Playing Game,TRPG)是一种基于故事和角色扮演的游戏,玩家会在一个设定好的虚拟世界中扮演虚构角色并展开冒险和互动。TRPG游戏的参与者通常为一名主持人(COC游戏中称为KP,Keeper of ArcaneLore,奥秘守密人;DND游戏中称为DM,Dungeon Master,地下城城主)和多名玩家,其中主持人负责创造游戏世界、设定情节、扮演非玩家角色(NPC)并引导游戏进程,玩家则自由控制自己所扮演的角色,通过角色行动和对话的方式推动故事发展。与电脑角色扮演游戏(Computer Role-Playing Game,CRPG)不同,TRPG无需电子软件辅助,而是通过面对面语言交互的方式进行。而与剧本杀相比,TRPG各个模组之间具有一定连续性和可养成性,每个模组针对玩家也会有些许变化,因此TRPG具有更强的可玩性与玩家粘性。
较为出名的TRPG游戏包括克苏鲁的呼唤(Call of Cthulhu, COC)和龙与地下城(Dungeons& Dragons, DND),它们也代表了两种不同类型的TRPG。其中COC侧重角色的技能和属性,DND侧重自由冒险和探索。虽然COC和DND的背景设置各异,例如COC纳入了疯狂值(Sanity)等特殊元素,而DND内置了丰富的剧情和任务,规则复杂度也有所不同,但是二者都强调玩家之间的互动和决策。近期拾象科技开发了一款以AI Agent为主持人的“盗梦笔记”游戏,目前处于内测阶段。盗梦笔记游戏共有自由幻想区、萌新区、阿卡姆和DND四个模块,其中自由幻想区和DND仍在开发中。
盗梦笔记萌新区接近传统TRPG游戏,玩家需要扮演侦探,在与AI Agent的交互中寻找故事真相。与COC类似,萌新区游戏拥有复杂而完善的角色设置体系,玩家在正式进入模组前需要先行设定自身角色的职业、技能等基本属性。以模组《追书人》为例,玩家在正式开启游戏后将扮演私家侦探探索托马斯·金博尔书房午夜响动的真相,而AI Agent则会扮演主持人设置游戏基本场景并引导玩家展开探索,并会在玩家偏离游戏主线时及时提醒。同时,AI Agent能够根据玩家技能释放成功与否自动生成不同回复,对游戏进程具有较充分的把握,也提高了玩家的游戏体验。
图表13:AI Agent能够作为主持人引导游戏进程
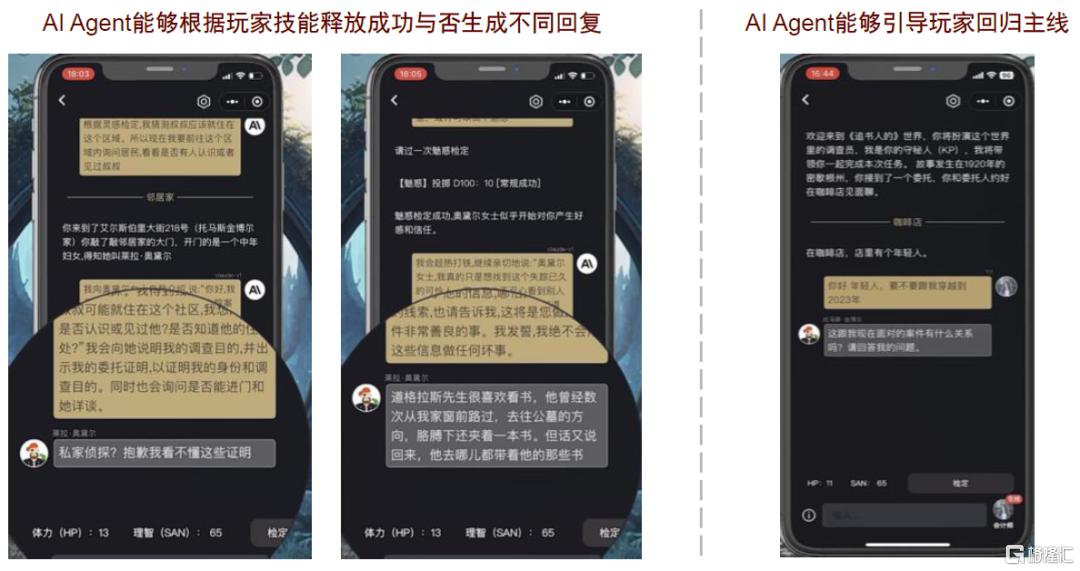
资料来源:海外独角兽公众号,中金公司研究部
而在阿卡姆小镇游戏中,200个由AI Agent扮演的角色需在同一虚拟城镇中共同生活十年,是多Agent协同的范本之一。阿卡姆小镇是克苏鲁神话系列小说中的一座虚构城市,游戏设定中其发生超自然事件的频率较高。在阿卡姆小镇生活的角色除额外拥有疯狂值属性外,其他特征均与常人类似,这意味着他们不仅会自主决策、彼此交互、做出行动并产生相关记忆,还会在目睹某些特定事件后丧失理智、陷入疯狂。游戏实验发现,若无外界介入,几乎所有AI Agent扮演的角色都会在十年后陷入疯狂,在对话时Agent也会输出一些浑浑噩噩的回复。而当玩家扮演的角色进入小镇并与Agent交互后,他们可能触发隐藏探索任务、阻止特定事件发生并改变Agent的记忆和行为,从而大幅改变前述“世人皆疯”的实验结局。
图表14:阿卡姆小镇:AI Agent能够彼此交互,并根据所扮演角色的状态生成相应对话

资料来源:bilibili平台盗梦笔记游戏官方账号,中金公司研究部
为给玩家带来更好的游戏体验,拾象科技主要采取了以下技术细节:1)选用多个大模型(例如OpenAI的GPT-4和Anthropic的Claude3)测试游戏效果,采用中等尺寸模型并利用阿卡姆小镇游戏数据和ChatGPT、Claude等外部大模型生成的语料对其进行微调(Finetune)[14],尽量避免大模型出现幻觉问题;2)减少上下文调用频率以降低上下文语义冲突的概率并节约成本;3)调用多个AI Agent兼任主持人,例如分别负责整体游戏规则理解、故事线生成、NPC情感、技能判定等,从而避免上下文遗忘和穿模;4)具备多Agent协作和记忆模块,在阿卡姆小镇中提取关键信息,并在每天12时同步;5)具备Function Calling模块,战斗场景中较好地融合了BUFF、武器和门禁系统等。
中金研究认为,AI Agent具备出色的记忆和语言交互能力,能够胜任主持人角色。TRPG的游戏剧本和规则设定动辄多达400余页,因此熟悉剧本对主持人而言是一项重大挑战。而AI Agent出色的记忆和语言交互能力能够使其在充分熟悉游戏剧本的基础上,根据玩家的反馈有序推进游戏进程,天然满足游戏主持人的要求。
风险提示
技术发展不及预期。目前UI多模态大模型仍处于相对早期的发展阶段,其技术进展存在一定不确定性;随着通用大模型持续迭代、垂直场景专有大模型不断涌现、Agent复杂程度不断增加,AI Agent或出现新的构建方式和落地形态。
商业化落地进展不及预期。目前融入UI交互模型的端侧Agent正处于产业探索的初步阶段,如何在终端设备释放AI Agent能力有待进一步研究,是否需要以及如何打破原有封闭生态也需要更多资源和利益角度的衡量。此外,若搭载UI模型的相关终端硬件能力升级和操作系统的迭代速度不及预期,也可能影响Agent落地节奏。
行业竞争加剧。面向智能交互的多模态大模型是端侧Agent落地的基石,近期海内外科技巨头和AI初创公司陆续推出UI识别和操作模型、类Agent产品,未来模型层和应用层的行业竞争可能会进一步加剧。
主:本文摘自中金研究于2024年5月26日已经发布的《人工智能十年展望(十九):渐行渐近的AI Agent:能力升级,场景创新》,分析师:于钟海 S0080518070011;魏鹳霏 S0080523060019;游航 S0080523010001;王倩蕾 S0080122090111;王之昊 S0080522050001



