 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
北京时间 4 月 19 日,Meta 重磅发布发布了其最先进开源大型语言模型的下一代产品——Llama 3,一夜间重新坐稳王者之位。

据悉,Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据,提供了 80 亿和 700 亿的预训练和指令微调版本。
Meta 在官方博客中表示,“得益于预训练和后训练的改进,我们的预训练和指令微调模型是目前 80 亿 和 700 亿 参数尺度下最好的模型。”
在Llama 3发布后,扎克伯格向外媒表示,“我们的目标不是与开源模型竞争,而是要超过所有人,打造最领先的人工智能。”

最强开源大模型,直逼 GPT-4
Meta 本次开源了 8B 和 70B 两款不同规模的模型。
Llama 3 8B:基本上与最大的 Llama 2 70B 一样强大。
Llama 3 70B: 第一档 AI 模型,媲美 Gemini 1.5 Pro、全面超越 Claude 大杯。
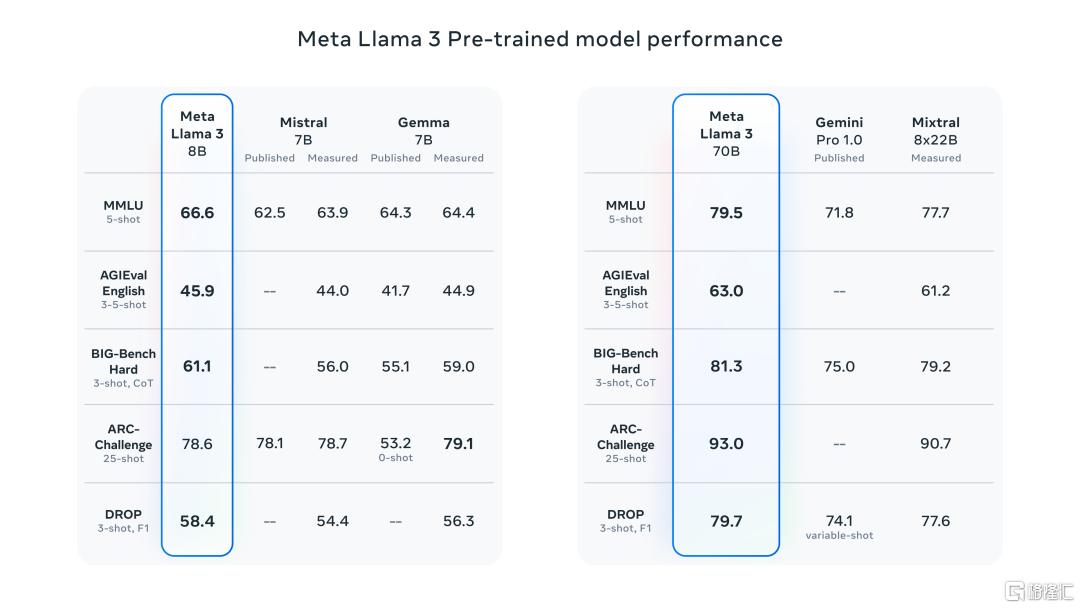
在MMLU、HumanEval和GSM-8K上,Llama 3 70B击败了Gemini 1.5 Pro。尽管无法与Anthropic性能最强的模型 Claude 3 Opus媲美,但 Llama 3 70B的性能,已经优于Claude 3系列的中杯模型Sonnet。

具体来说,Llama 3的亮点和特性概括如下:
基于超过15T token训练,大小相当于Llama 2数据集的7倍还多;
训练效率比Llama 2高3倍;
支持8K长文本,改进的tokenizer具有128K token的词汇量,可实现更好的性能;
在大量重要基准测试中均具有最先进性能;
增强的推理和代码能力;
此次的大模型通过后期训练程序上的改进很大程度上降低了 Llama 3 的错误拒绝率,提高了对齐度,并增加了模型响应的多样性。Meta 研发团队还发现,推理、代码生成和指令跟随等能力也有了很大提高,这使得 Llama 3 的可操控性更强。
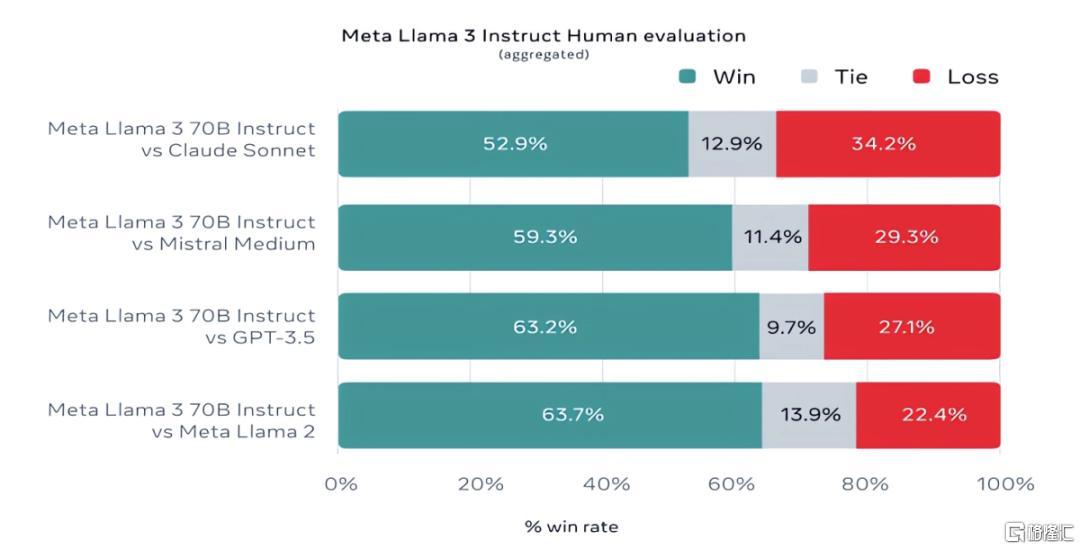
与前代 Llama 2 模型相比,Llama 3 可谓是迈上了一个新的台阶。
80 亿参数模型与 Gemma 7B 和 Mistral 7B Instruct 等模型相比在 MMLU、GPQA、HumanEval 等多项基准上均有更好表现。而 700 亿参数模型则超越了闭源超级明星大模型 Claude 3 Sonnet,且与谷歌的 Gemini Pro 1.5 在性能上不相上下。
据Meta介绍,Llama 3将被整合到其虚拟助手Meta AI中,这是免费使用的同类产品中最先进的AI应用程序。Meta AI助手已经在Facebook、Instagram、WhatsApp和Messenger等应用中上线,随后也将迎来更新。
Meta首席产品官Chris Cox在接受采访时说,这家社交媒体巨头为Llama 3配备了新的计算机编码能力,这次除了可以输入文本外,还可以输入了图像,不过目前该模型只能输出文本内容。因此,Llama 3目前还不是多模态大模型。
但他补充说,更高级的推理能力,比如制定更长的多步骤计划的能力,将在随后的版本中出现。并计划在未来几个月发布多模态版本,这意味着它们可以同时生成文本和图像。
值得注意是,以上还只是 Meta 的开胃小菜,真正的大餐还在后头。在未来几个月,Meta 将陆续推出一系列具备多模态、多语言对话、更长上下文窗口等能力的新模型。其中,超 400B 的重量级选手更是有望与 Claude 3 超大杯“掰手腕”。
Llama 3 的到来,也在社交平台 X 上掀起一股新的讨论风暴。
Meta AI 首席科学家、图灵奖得主 Yann LeCun 不仅为 Llama 3 的发布摇旗呐喊,并再次预告未来几个月将推出更多版本。

就连马斯克也现身于该评论区,用一句简洁而含蓄的「Not bad 不错」,表达了对 Llama 3 的认可和期待。
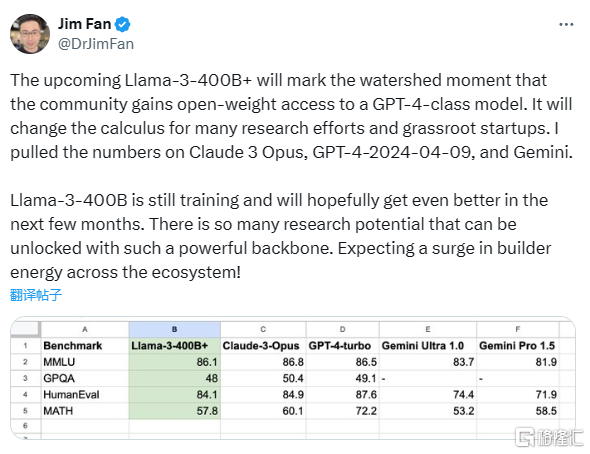
英伟达高级科学家Jim Fan认为之后可能会发布的Llama 3-400B以上的版本其将成为某种“分水岭”,开源社区将能用上GPT-4级别的模型。他做了一个对比图,可以看到,Llama 3 400B已经在多语言推理任务、代码能力,可与GPT-4、Claude 3相匹敌。更亮眼的是,它在所有能力上,均打败了Gemini Ultra 1.0。
附模型下载链接:https://llama.meta.com/llama-downloads/
GitHub项目地址:https://github.com/meta-llama/llama3



